
Programming
We distinguish between concurrent programming that focuses on problems where concurrency is part of the specification (reactive code such as an operating system, user interfaces, or on-line transaction processing, etc.), and parallel programming that focuses on problems where concurrent execution is used only for improving the performance of a transformational code. The prevalence of multicore platforms does not increase the need for concurrent programming and does not make it harder; it increases the need for parallel programming. It is our contention that parallel programming is much easier than concurrent programming; in particular, it is seldom necessary to use nondeterministic code.
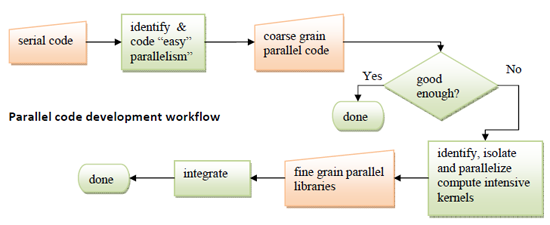
The figure below represents a very schematic view of the parallel software creation process. One will often start with a sequential code, although starting from a high-level specification is preferred. It is often possible to identify “outer loop” parallelism where all or most of the sequential code logic can be encapsulated into a parallel execution framework (pipeline, master-slave, etc.), with little or no change in the sequential code. If this is not sufficient to achieve the desired performance, then one identifies compute intensive kernels, encapsulates them into libraries, and tunes these libraries to leverage parallelism at a finer grain, including SIMD parallelism. While the production of carefully tuned parallel libraries will involve performance coding experts, simple, coarse-level parallelism should be accessible to all.
We propose to help “simple parallelism” by developing refactoring tools that help converting sequential code into parallel code that uses existing parallel frameworks in C# or Java and debugging tools that help identify concurrency bugs. More fundamentally, we propose to support simple parallelism with languages that are deterministic by default and concurrency safe.
Languages such as Java and C# provide safety guarantees (e.g., type safety or memory safety) that significantly reduce the opportunities for hard to track bugs and improve programmer’s productivity. We plan to bring the same benefits to parallel and concurrent programming: a concurrency safe language prevents, by design, the occurrence of data races. As a result, the semantics of concurrent execution is well-defined, and hard-to-track bugs are avoided.
A deterministic by default language will also ensure that, unless explicit nondeterministic constructs are used, any execution of a parallel code will have the same outcome as a sequential execution. This significantly reduces the effort of testing parallel code and facilitates the porting of sequential code. Our work on Deterministic Parallel Java (DPJ) shows that both properties can be satisfied, even for modern object-oriented programming, without undue loss of expressiveness, and good performance. Moreover, the deterministic guarantee can be enforced with simple, compile-time type checking, which has major benefits. Although such a safe language requires some initial programming effort, these efforts are small compared with that of designing and developing a parallel program and can be significantly reduced via interactive porting tools Our tool, DPJizer, can infer much of the added information required by DPJ. The effort has a large long-term payoff in terms of greatly improved documentation, maintainability, and robustness under future software changes.
The effort has a large long-term payoff in terms of greatly improved documentation, maintainability, and robustness under future software changes.
The development of high-performance parallel libraries requires a different environment that enables programmers to work more closely to the iron, and facilitate porting and tuning for new platforms. We believe that such work should happen in an environment where compiler analysis and code development interact tightly, so that the performance programmer works with the compiler, not against it, as is often the case today. We are working on refactoring environments where code changes are mostly annotations that add information not otherwise available in the source code. The annotation information is extended by advanced compiler analysis to enable robust deployment of transformations such as data layout adjustment and loop tiling transformations. One particular goal of our Gluon work is to enable portable parallel code base for both fine-grained engines such as GPUs and coarser grained multi-core CPUs, as well as their associated memory hierarchies. Autotuning by manipulating the algorithm or the code is another technique we apply to this problem.
Parallel libraries are most easily integrated into sequential code when they follow the SIMD (Single Instruction stream, Multiple Data stream) model. Our work on Hierarchical Tiled Arrays (HTA) confirms earlier results showing that the effectiveness of this model is not confined to the traditional array computations and can be used to support a wide range of complex applications with good performance. The use of tiles as a first class object gives programmers good control of locality, granularity, and load balancing.
The integration of parallel libraries and frameworks into a concurrency safe programming environment requires a careful design of interfaces to ensure that the safety guarantees are not violated. We can use simple language features as specialized “contracts” at framework interfaces to ensure that client code using a parallel framework (with internal parallelism) does not violate assumptions made within the framework implementation. Such an approach gives the (presumably) expert framework implementer freedom to use low-level and/or highly tuned techniques within the framework while enforcing a safety net for (presumably) less expert application programmers using the framework. The expert framework implementation can be subject to extensive testing and analysis techniques, including proofs of concurrency safety using manual annotations.
Research Areas
- Autotuning
- Gluon: Interface for Trusted Programming
- Interactive Porting to New Parallel Programming Models
- Libraries
- Optimizations for Power
- Refactoring
- Safe Parallel Programming Languages: DPJ and DPC++
- Scheduling: Sequential Performance Models for Parallel Programming
- Verification and Validation